Data privacy in financial automation: a practical guide

Automation now processes millions of financial records daily, and the speed gains are real. Case studies show 52x productivity gains in automated financial data analysis alongside 90% cost reductions. But every document that moves through an automated pipeline carries sensitive data, and one misconfigured workflow can expose account numbers, Social Security numbers, and transaction histories at scale. This guide walks financial controllers and data analysts through the specific risks, the technologies that address them, and the practical steps to build privacy into automated financial document processing from day one.
Table of Contents
- Why data privacy matters in financial automation
- How automation exposes sensitive financial data
- Core privacy-enhancing technologies for financial workflows
- Nuanced privacy challenges: AI, compliance, and innovation
- Practical steps to enhance data privacy in automated financial workflows
- How BankStatementFlow supports privacy-first financial automation
- Frequently asked questions
Key Takeaways
| Point | Details |
|---|---|
| Automation increases privacy risk | Scaling automated financial workflows without robust controls can expose sensitive data to new threats. |
| Hybrid AI solutions work best | Combining NLP and ML delivers higher accuracy for PII detection and anonymization than a pure AI or rule-based approach. |
| Edge cases require vigilance | Quasi-identifiers, AI hallucinations, and unstructured documents introduce additional risk that mandates extra controls. |
| Privacy boosts efficiency and trust | Strong privacy controls not only ensure compliance but also yield cost savings and user trust in financial automation. |
Why data privacy matters in financial automation
Speed and cost reduction are compelling reasons to automate, but they can create blind spots around data governance. Financial teams operating at scale face a layered set of obligations under regulations like GLBA, PCI DSS, and GDPR. A single breach does not just trigger fines. It can freeze automation initiatives, invite regulatory audits, and permanently damage client relationships.
The financial cost of getting this wrong keeps rising. Privacy tech market spending now exceeds $218 billion annually, driven largely by compliance requirements that GDPR and similar frameworks impose. That figure reflects how seriously enterprises are investing in privacy infrastructure, not just legal counsel.
Here is what is actually at stake for your team:
- Regulatory exposure: Non-compliance with GLBA, PCI DSS, or GDPR can result in fines, mandatory audits, and operational restrictions.
- Reputational risk: Clients and partners lose confidence quickly when financial data is mishandled, even if no fraud occurs.
- Automation disruption: A breach or compliance failure can force a full halt of automated workflows while investigations proceed.
- Third-party liability: Vendors and integrations that touch your data extend your risk surface significantly.
“Privacy is not a feature you add to automation. It is the foundation that determines whether automation is sustainable at scale.”
The role of automation in financial reporting is expanding fast, and that expansion demands equally fast maturity in data governance. Teams that treat privacy as an afterthought will face compounding risk as their document volumes grow. The good news is that the regulatory pressure driving compliance costs is also pushing the development of better, more accessible privacy tools.
How automation exposes sensitive financial data
Regulations and trust set the stakes, but where exactly are the cracks as automation takes over? The answer is often not a dramatic hack. It is a quiet misconfiguration or an overlooked data flow.

Unstructured documents are the primary danger zone. PDFs, Excel files, scanned invoices, and bank statements all contain personally identifiable information (PII) in formats that automated systems can inadvertently copy, store, or forward without proper controls. When these documents move through cloud-shared folders, email integrations, or third-party analytics tools, PII can end up in environments with far weaker security than your core systems.
Modern AI introduces its own category of risk. NLP and ML financial privacy research highlights three specific threats that financial teams need to understand:
- Hallucinations: AI models can generate plausible but incorrect data, which is dangerous when outputs feed into financial records or compliance reports.
- Prompt injection: Malicious inputs can manipulate AI agents into leaking or mishandling sensitive data.
- Quasi-identifier re-identification: Combining non-sensitive fields like zip code, employer, and transaction date can re-identify individuals even after obvious PII is removed.
“The most dangerous data exposure in financial automation is not the breach you detect. It is the slow leak you never notice.”
Automated workflows also create test environment risks. Developers frequently copy production data into staging environments to test new features, and that data often retains full PII. AI-powered PII detection with permanent redaction addresses this directly, with benchmarks showing a 96.5% field match rate and a 67.9% reduction in processing time compared to manual approaches. Understanding AI in fraud detection also helps teams recognize where AI risk overlaps with privacy risk in financial workflows. For teams scaling AI regulatory compliance in finance, mapping these exposure points is the first step toward closing them.
Core privacy-enhancing technologies for financial workflows
With risks mapped out, let’s move to the tools and tech strategies that actually deliver results. Not all privacy technologies are equal, and the right choice depends on your document types, processing volume, and regulatory obligations.
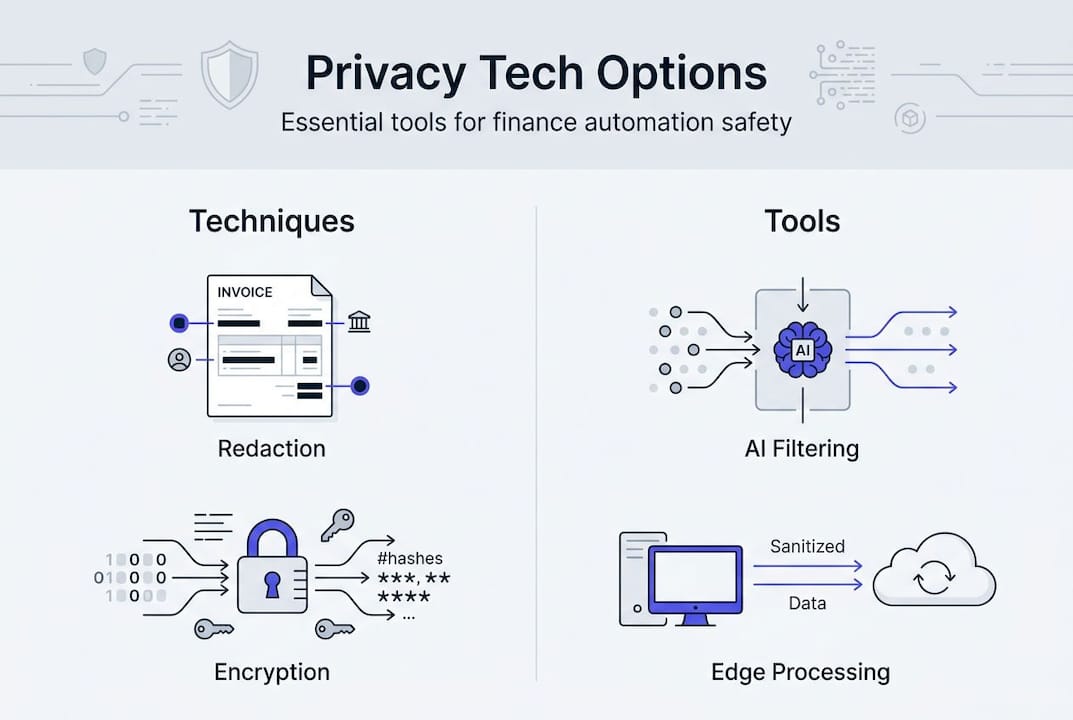
Comparison of key PII protection approaches
| Approach | Accuracy | Best for | Key limitation |
|---|---|---|---|
| Rule-based redaction | Moderate | Structured, predictable formats | Fails on unstructured or varied layouts |
| ML-driven redaction | High | Complex, multi-format financial docs | Requires training data and tuning |
| Hybrid NLP and ML | Highest | Enterprise-grade financial workflows | Higher implementation complexity |
| On-device redaction | Variable | Sovereignty and low-latency needs | Limited scalability for large volumes |
| Cloud redaction | High | High-volume, scalable pipelines | Requires strong vendor security controls |
Hybrid NLP and ML approaches achieve 89.4% accuracy and 94.7% precision in PII detection across financial documents. That is a meaningful gap above rule-based systems, which struggle when document layouts vary across vendors, regions, or document types. For financial teams processing bank statements, invoices, and receipts from multiple sources, hybrid approaches are the practical standard.
Privacy-by-design is the architectural principle that ties these tools together. Rather than layering privacy controls onto an existing workflow, privacy-by-design automation integrates safeguards at every processing step: ingestion, transformation, storage, and export. This means PII is identified and handled before it ever reaches analytics layers or third-party integrations.
Here is a prioritized implementation sequence for financial teams:
- Audit your current document flows to identify where PII enters, moves, and exits your systems.
- Select a redaction approach based on your document variety and volume. Hybrid ML-NLP is the benchmark for AI accuracy in bank statement processing.
- Implement role-based access controls (RBAC) so only authorized users can access unredacted data.
- Apply on-device or edge redaction for documents with high sovereignty requirements.
- Validate outputs with automated accuracy checks before data moves downstream.
Pro Tip: If your team processes documents from multiple countries, prioritize a platform that handles regional formats and multi-language PII detection natively. Retrofitting language support after deployment is expensive and error-prone. AI for high-accuracy document processing covers how modern platforms handle this at scale.
Nuanced privacy challenges: AI, compliance, and innovation
Now, let’s talk about the complexities that even advanced tech cannot entirely neutralize. Financial automation in 2026 operates in a regulatory environment that is still catching up to the technology it governs.
Key challenge areas for financial teams
| Challenge | Risk level | Mitigation approach |
|---|---|---|
| Quasi-identifier re-identification | High | Differential privacy, k-anonymity |
| AI hallucinations in outputs | Medium-High | Output validation, human review triggers |
| Unstructured data in PDFs and Excel | High | Multi-format ML redaction pipelines |
| Data sovereignty across jurisdictions | High | On-device or regional cloud processing |
| Prompt injection in AI agents | Medium | Input sanitization, sandboxed environments |
Quasi-identifiers in financial documents are a persistent challenge. Fields like employer name, transaction amount, and account type are not PII on their own, but combined, they can re-identify individuals with high confidence. Unstructured formats like PDFs and Excel files require consistent anonymization across every field, and that consistency is hard to enforce without purpose-built tooling.
Regulatory complexity adds another layer. Privacy regulations drive innovation but also raise costs, and fintechs and incumbent banks face different incentives. Fintechs often view data sharing as a competitive advantage, while larger institutions prioritize security and liability management. Risk-based Data Protection Impact Assessments (DPIAs) are essential for any enterprise deploying automated financial workflows, because they force a structured evaluation of where automation creates new privacy exposure.
The future of AI in fintech will bring more capable models, but also more complex risk profiles. Teams that build observability into their automation stack now will be better positioned to detect bias, hallucinations, and compliance drift before they become incidents. External audits and continuous monitoring close the gaps that internal teams often miss. Data management for automation provides a practical framework for keeping these controls current as your workflows evolve.
Pro Tip: Do not treat DPIAs as a one-time compliance exercise. Run them whenever you add a new document type, integrate a new vendor, or expand into a new jurisdiction. The privacy in fintech innovation landscape shifts fast enough that annual reviews are insufficient for most enterprise teams.
Practical steps to enhance data privacy in automated financial workflows
Understanding challenges is crucial, but what should you do differently in your organization today? Here is a structured approach that financial controllers and data analysts can act on immediately.
Step-by-step implementation framework:
- Map your PII flows. Document every point where financial data enters, is processed, stored, or exported. Include third-party integrations and test environments.
- Implement privacy-by-design at ingestion. Apply AI-powered PII redaction before data moves into any downstream system. Automating secure financial data workflows with zero-trust architecture and ELT pipelines ensures PII is handled at the earliest possible stage.
- Configure role-based access controls. Limit access to unredacted data to only those roles that require it for specific business functions.
- Set up audit logging. Every access, transformation, and export event should be logged with timestamps and user identifiers.
- Run automated accuracy validation. Before processed data reaches analytics or reporting layers, validate field match rates and flag anomalies for review.
- Schedule regular DPIAs. Tie these to workflow changes, not just calendar dates.
Common pitfalls to avoid:
- Over-redaction removes data that auditors and analysts legitimately need, creating gaps in financial records and complicating compliance reviews.
- Insufficient RBAC means that even well-redacted data can be accessed by unauthorized users after the fact.
- Skipping test environment controls exposes production PII to developers and QA teams who do not need it.
- Treating vendor security as your own without independent verification creates blind spots in your risk model.
Pro Tip: Use compute-to-data or edge redaction architectures wherever possible. These approaches process documents locally before any data leaves your environment, which minimizes PII transit risk and simplifies data sovereignty compliance across jurisdictions.
How BankStatementFlow supports privacy-first financial automation
Building privacy into automated financial workflows is not a theoretical exercise. It requires tooling that handles real-world document complexity without sacrificing accuracy or speed.
BankStatementFlow is built for exactly this environment. The platform applies AI-powered extraction and redaction to bank statements, invoices, receipts, and other financial documents, converting unstructured data into structured formats like Excel, CSV, JSON, and XML with up to 99% accuracy. Enterprise security controls, role-based access, and support for password-protected and encrypted PDFs are built into the core platform, not added as optional features. For teams processing documents across multiple regions and languages, BankStatementFlow handles regional formats natively, and its API integration means privacy controls apply consistently across your existing workflows. If your team is ready to automate without compromising on data governance, BankStatementFlow is the practical next step.
Frequently asked questions
What is the most effective technology for PII redaction in financial documents?
Hybrid NLP and ML approaches deliver the highest accuracy for PII detection in financial documents, achieving 89.4% accuracy and 94.7% precision across varied document formats.
How do privacy regulations impact financial automation initiatives?
They increase compliance costs and operational complexity, but they also drive privacy tech adoption and build customer trust, with global spending on privacy technology now exceeding $218 billion annually.
What are quasi-identifiers and why are they a challenge?
Quasi-identifiers are individual data fields that seem harmless alone but can combine to re-identify a person. Unstructured financial documents like PDFs and Excel files make consistent anonymization of these fields especially difficult.
How can I reduce the risk of AI hallucinations or bias in financial automation workflows?
Implement observability tools that monitor AI outputs continuously and use hybrid privacy-by-design solutions that include output validation layers rather than relying on generative AI without checks.
Recommended
- Optimize secure financial data workflows with automation - BankStatementFlow Blog
- Financial data management checklist for automation 2026 - BankStatementFlow Blog
- What is financial document automation? A 2026 guide - BankStatementFlow Blog
- Master financial document organization: 99% accuracy guide - BankStatementFlow Blog
- Mithril Money - Automated Trading Strategies & DeFi Tools